In our last entry, we ended by giving a brief overview of what a neural network is (from a more mathematical perspective). In this, we indicated that it is:
However, before we move forward, we need to take a step back and briefly discuss the origins and inspiration of neural networks (which eventually leads to the more mathematical definition above).
Inspired by neurons in the biological brain, scholars in the 20th century (Warren McCulloch, Walter Pitts, Frank Rosenblatt, among others) sought to replicate how the brain works to achieve computation functions[1]. This effort has progressed into what it is today, of which key, well-established concepts now include:
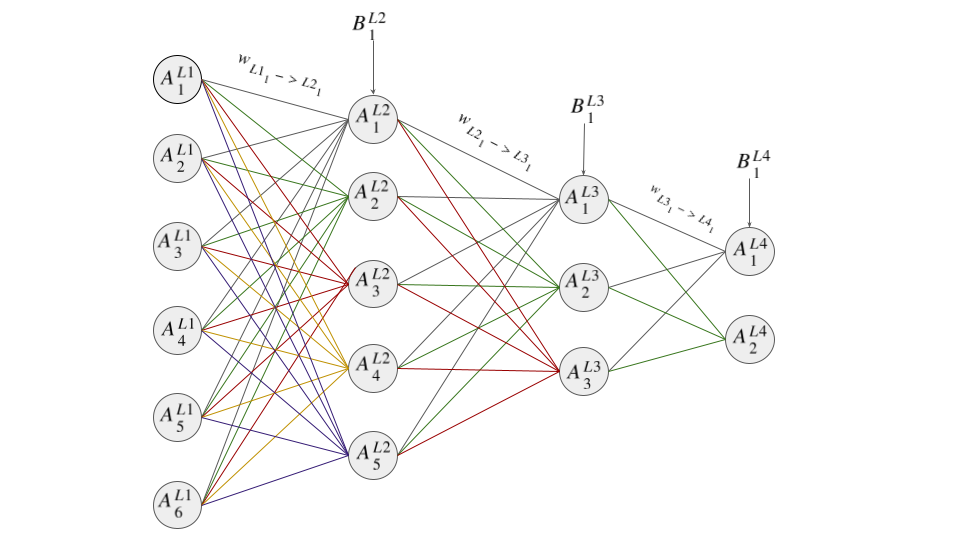
Diagrammatically this can be represented as:
As can be deduced from the above diagram, each neuron's value is a function of the value of
the connecting node (neuron), its weight, and its bias. In fact, the formula for the value
of each neuron/node is 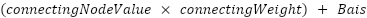
The values are then chained together as can be seen above (i.e The values, 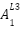 ,
, 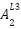 and
and 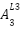 feed into
feed into 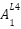 ).
And since each node value is in essence a function, we can say a neural network is a chain of
functions that produces a final result.
).
And since each node value is in essence a function, we can say a neural network is a chain of
functions that produces a final result.
Forward and backward propagation
The process of getting the output for a given input (i.e., moving from input to output) is known as forward propagation.
The process of updating the weights and biases after calculating the cost function is known as back propagation. This term is used because the process starts from the output nodes and works its way backwards, updating the nodes and weights.
Note: In machine learning libraries like PyTorch and TensorFlow, the specific implementation of forward and back propagation is often referred to as the optimization strategy. As highlighted in our previous entry, although there are quite a few strategies (see link for the most common), they are all rooted in gradient descent.
For all our neural networks, we will be using the Stochastic Gradient Descent (SGD) strategy. Although not the most popular strategy in real-world use cases (see Adam), it is the best suited for learning how neural networks work, as it keeps the nuances to a minimum.
Cost Functions
In addition to this, the loss function (explained in the previous entry) we will be using is the Mean Squared Error (MSE). Similar to the optimization strategy we chose, other cost functions in real-world use cases are used (e.g Cross-Entropy), but from a learning perspective, it is more accessible and keeps complexity to a minimum.
Activation Function
The next thing we need to introduce is the activation
function (usually denoted as
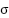 in most neural network
content). Mathematically, it is
a function that introduces non-linearity, mapping a node's value to a defined, often curved,
boundary. Rather than dwelling on the technical details, you can view the
activation function as a mechanism that standardizes the output value for a node/neuron, which is essential
for the network's ability to learn complex patterns.
in most neural network
content). Mathematically, it is
a function that introduces non-linearity, mapping a node's value to a defined, often curved,
boundary. Rather than dwelling on the technical details, you can view the
activation function as a mechanism that standardizes the output value for a node/neuron, which is essential
for the network's ability to learn complex patterns.
This means that if the value of our node is (as described above):
The final value will be:
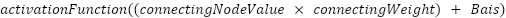
There are a few activation functions that can be used in neural networks, including the Sigmoid, ReLU (Rectified Linear Unit), and Tanh (Hyperbolic Tangent) functions. We will be using the Sigmoid function in our neural network. This choice, similar to our selection of the optimization strategy and cost function, is made to simplify the conceptual understanding of the neural network's operation (note: ReLU is another very common choice in real-world applications).
Data Preprocessing - feature scaling - Normalization / standardization
The last thing we will cover before moving on to our sample example is data preprocessing. As the name suggests, this involves processing your data before you pass it on to your machine learning algorithm. There are a few aspects to this, of which you can read more on your own (as this falls more into the realm of general data science). The one aspect we will, however, highlight is that of normalization or standardization.
Normalization and Standardization are both feature/input scaling techniques that modify the range of your feature/input values, yet still maintain the relationship between them. This allows each feature to contribute more equally to training your model. To exemplify this, imagine if one of your inputs had a large range compared to other features (e.g., property price compared to an aesthetic score out of 10). Without feature scaling, it could dominate the training, resulting in a skewed model.
Due to this, it is important to check your data and normalize or standardize as appropriate before training. P.S. Please see the link regarding which technique is best suited for your data.
Okay, now that we have all the main concepts out of the way, let's actually see how a neural network works in practice.
[1] https://www.ibm.com/think/topics/neural-networks#:~:text=A%20neural%20network%20is%20a,from%20forecasting%20to%20facial%20recognition.